Redis
Redis
缓存更新策略

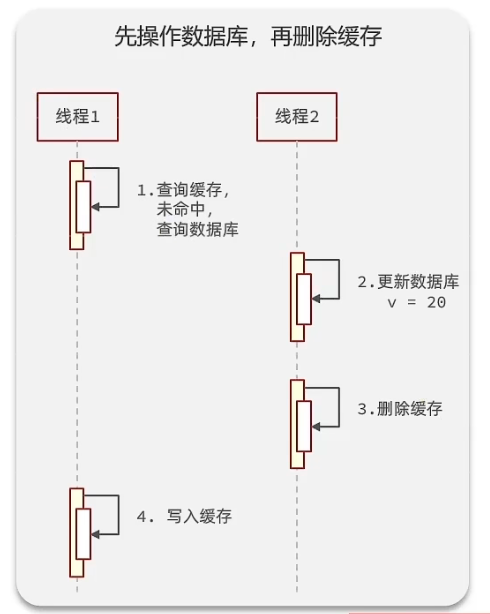
1.先删缓存再删数据库:可能发生线程1删除缓存后但是未更新数据库前,线程2去查询,导致从数据库中查询到旧数据,并且重新写入缓存。之后线程1才对数据库进行更新
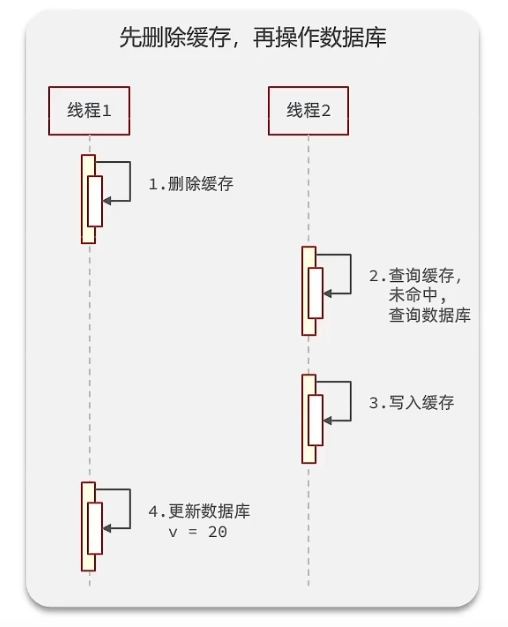
2.先删数据库再删缓存:可能发生线程1去查询缓存的时候查不到,从而去数据库中查询到旧数据,然后此时线程2对数据库进行更新并删除缓存后,线程1又把旧数据写入缓存。但是可能性较小,因为写入缓存的时间远小于更新数据库的时间,所以一般情况下都只会是线程1把旧数据写入缓存后,线程2才更新数据库并且删除缓存。
缓存穿透
缓存穿透是指在查询缓存中不存在的数据,每次请求都会直接查询数据库或其他存储介质,从而造成请求过多、资源浪费等问题。这种情况常出现在恶意攻击或误操作等场景中。
解决方案
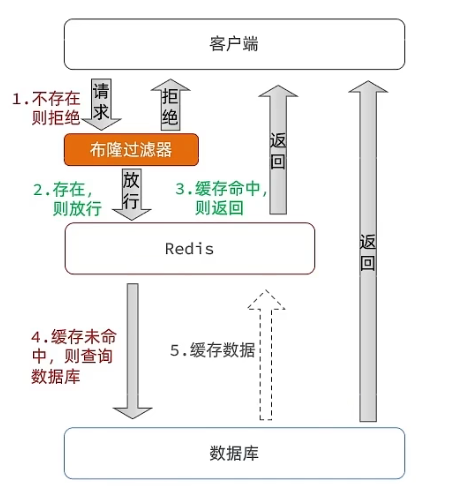
布隆过滤器:在查询缓存前,使用布隆过滤器预先判断请求的键是否存在,从而减轻数据库压力。
布隆过滤器(Bloom Filter)是一种常用的碰撞检测数据结构,可以用来判断一个元素是否在集合中。它由一个位数组和多个哈希函数组成,其中位数组中的每个元素都只能取 0 或 1 两个值。
在使用布隆过滤器前,需要预先设置位数组的长度和哈希函数的个数。当要加入一个新元素时,会先经过多个不同的哈希函数,将元素映射到位数组中的多个位置上,并将这些位置的值置为 1。而在查询元素是否在集合中时,同样会经过这些哈希函数,获取元素哈希值对应的多个位数组位置,只要有任何一个位置的值为 0,则说明该元素不在集合中,如果所有的位数组位置值都为 1,则说明该元素可能在集合中或有其他元素冲突,因此需要再进一步验证。
布隆过滤器的性能优点在于,它可以在常数时间内判断一个元素是否在集合中,即使元素数量很大,而且占用的空间也比较小。但是,布隆过滤器也有缺点,即存在一定的误判率,即已存在的元素可能被误认为不存在于集合中,这是因为哈希函数映射到位数组位置时可能会产生冲突。但是,误判率可以通过调整哈希函数个数和位数组长度来控制。

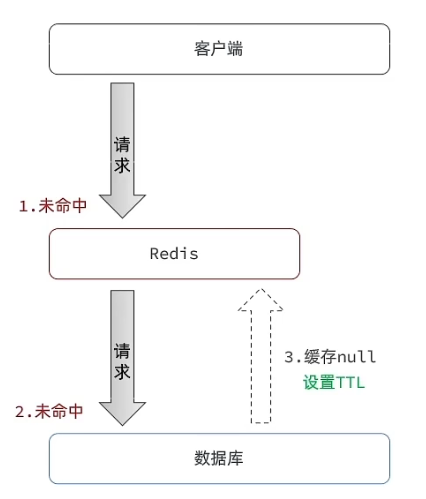
缓存空对象:将请求的键值对应的值设置为空对象,在下一次请求时,可以直接从缓存中获取。

缓存雪崩
缓存雪崩是指因为缓存中的大量数据同时失效或被清空,导致大量的请求直接打到数据库造成宕机或响应时间变得极长的现象。缓存雪崩通常会发生在一个较长时间内,由于请求量大、压力集中,导致系统崩溃。
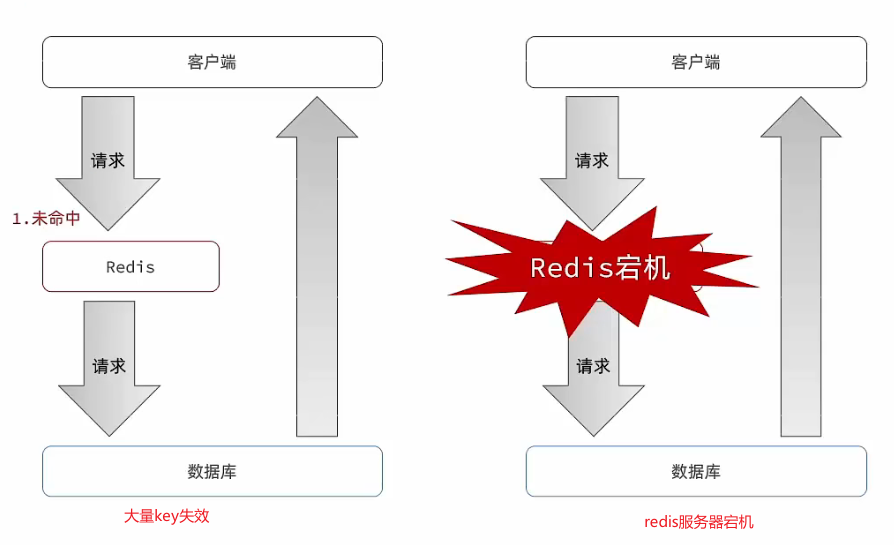
解决方案
◆给不同的Key的TTL添加随机值(避免同时到期)
◆利用Redis集群提高服务的可用性(避免redis宕机)
◆给缓存业务添加降级限流策略(牺牲服务,保护数据库)
◆给业务添加多级缓存(除redis外设立其他缓存)
缓存击穿
缓存击穿指的是一个存在缓存中但过期了的数据,在缓存失效的短时间内,有大量的请求同时涌入后端数据库或其他存储介质中进行查询,从而导致数据库或存储介质的访问压力过大,甚至可能引起服务崩溃的一种现象。为了避免缓存击穿,我们需要保证缓存的稳定性和可靠性,对于高访问频率或高并发的数据需要采用多重保障措施,避免频繁访问数据库,从而提高系统的稳定性和性能。
解决方案
1.互斥锁:性能较差
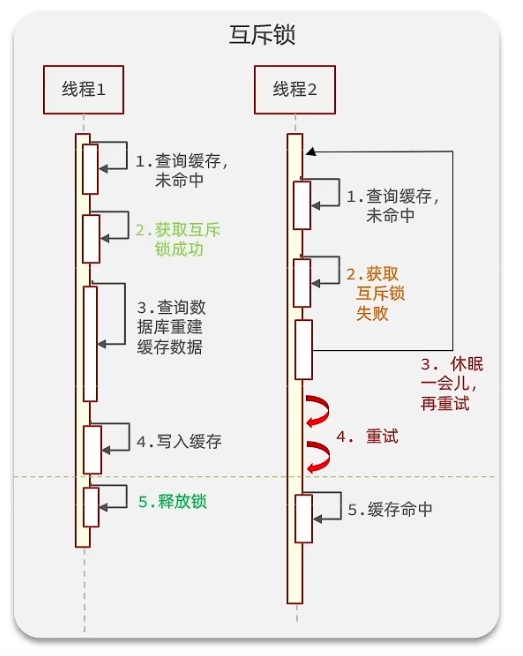
2.逻辑过期:不设置ttl,在存入的数据中自行设置过期时间。发现过期了就拿锁并开启新线程去重建缓存数据,但是不会等待重建完成,而是直接先返回旧数据。
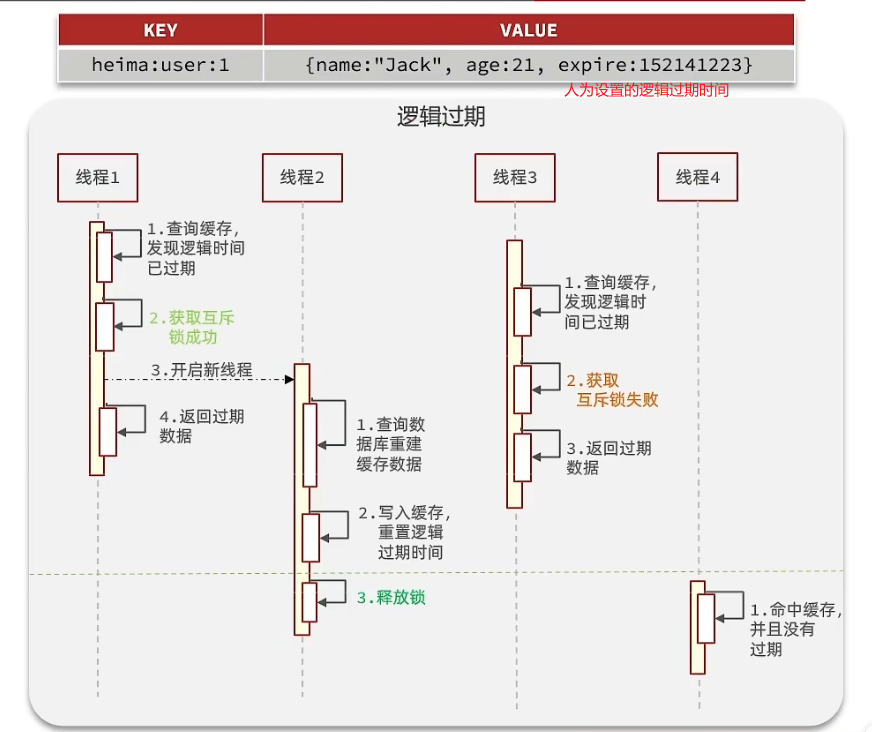
对比:
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | ●没有额外的内存消耗 ●保证一致性 ●实现简单 |
●线程需要等待,性能受影响 ●可能有死锁风险 |
| 逻辑过期 | ●线程无需等待,性能较好 | ●不保证一致性 ●有额外内存消耗 ●实现复杂 |
和缓存穿透的区别
生命周期不同:缓存击穿指的是一个存在缓存中但过期了的数据,在缓存失效的短时间内,有大量的请求同时涌入后台数据库或其他存储介质中进行查询,从而导致数据库或存储介质的访问压力过大的一种现象。
而缓存穿透则是指查询一个不存在的数据,即缓存和数据库中都没有该数据,导致每次查询都要到数据库中查找,从而导致数据库查询压力过大。
发生原因不同:缓存击穿通常是由于一个热点数据失效或没有缓存而引起的,
而缓存穿透要么是因为缓存中的数据不足以支持所有的查询,要么是因为攻击者恶意查询一些不存在的数据,造成无效查询。
解决方法不同:解决缓存击穿的方法主要是设置热点数据永久缓存,使用分布式锁等技术防止多个线程同时访问后端数据库,或者使用备用缓存等手段。
解决缓存穿透的方法主要是设置缓存空对象,例如将不存在的数据的缓存设置成一个空对象,避免重复查询,同时使用布隆过滤器等技术防止恶意查询。
秒杀案例
超卖问题
参考: 实战篇-05.优惠券秒杀-库存超卖问题分析_哔哩哔哩_bilibili
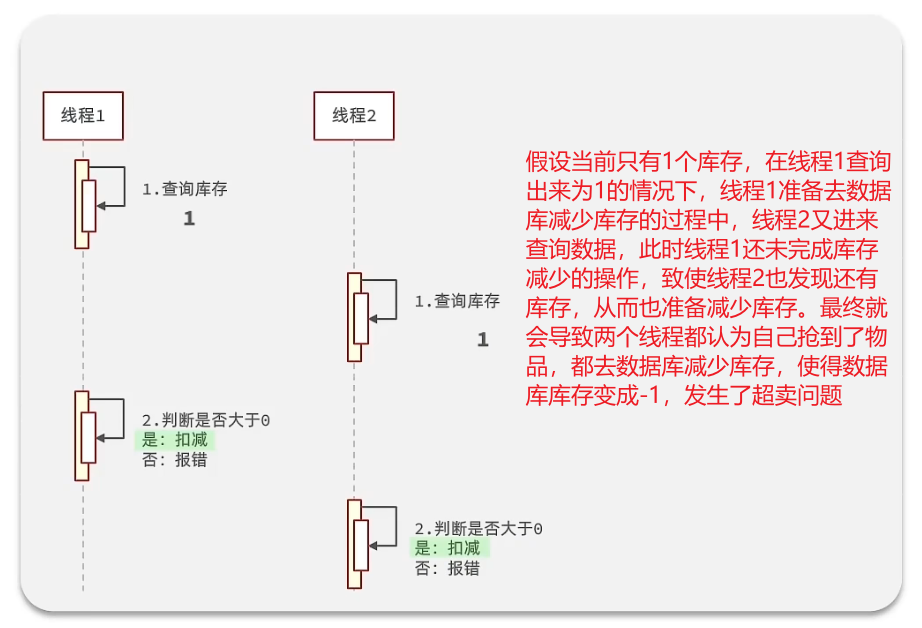
上面判断是否大于0是通过一开始查询库存查出来的数据来判断的。
解决方法:使用CAS(compare and set)法,用库存量来代替乐观锁本身的版本号法,每次更新比较一下库存是否有变化,没变化才更新。但这种情况下会造成失败率过高,所以可以将条件从等于改为库存>0就行(等于就是去减库存的时候再判断一下库存是不是大于0)
一人一单
参考:实战篇-07.优惠券秒杀-实现一人一单功能_哔哩哔哩_bilibili
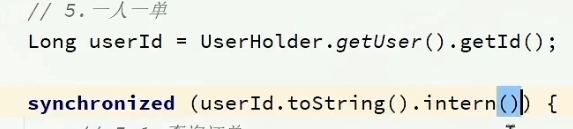
判断该用户是否已经参与过抢购,为避免并发问题需要使用悲观锁,以用户id为锁,利用intern(去常量池中找字符串值相同的对象,返回它的引用)保证用户id相同时,锁就相同

集群模式下上诉方法失效:实战篇-08.优惠券秒杀-集群下的线程并发安全问题_哔哩哔哩_bilibili
集群下,每台服务jvm不同,只能控制自己服务下的锁
分布式🔒
分布式锁是一种用于解决分布式系统中并发访问共享资源的问题的机制。在分布式系统中,多个应用程序可能会同时访问同一个共享资源,例如数据库、分布式缓存或消息队列等,如果不采取措施限制对该资源的访问,可能会导致数据不一致或其他问题。
分布式锁主要解决以下两个问题:
多个客户端并发访问某个共享资源时,需要保证只有一个客户端能够访问该资源,防止数据的异常、错乱或丢失。
如果分布式系统中的多个节点操作同一个共享资源,需要保证所有节点之间的操作顺序是一致的,防止出现竞争和死锁等问题。
分布式锁有多种实现方式,比如使用数据库、分布式缓存和ZooKeeper等。其中,使用ZooKeeper实现分布式锁是较为常见的一种方法。
实战篇-09.分布式锁-基本原理和不同实现方式对比_哔哩哔哩_bilibili
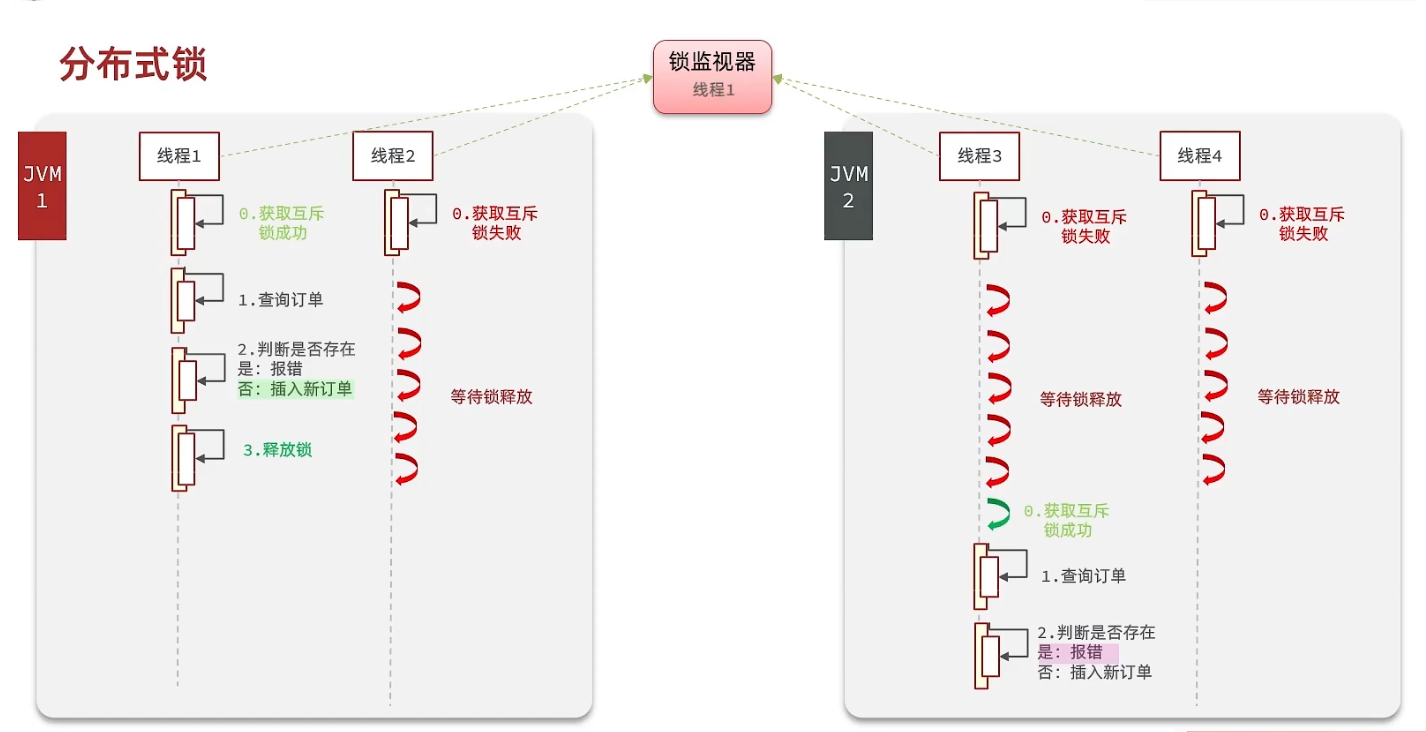
简单来说就是不使用jvm内部本身的锁监视器,而是使用一个共享的锁监视器(多进程可见、互斥、高可用、高性能、安全性)
分布式锁的实现
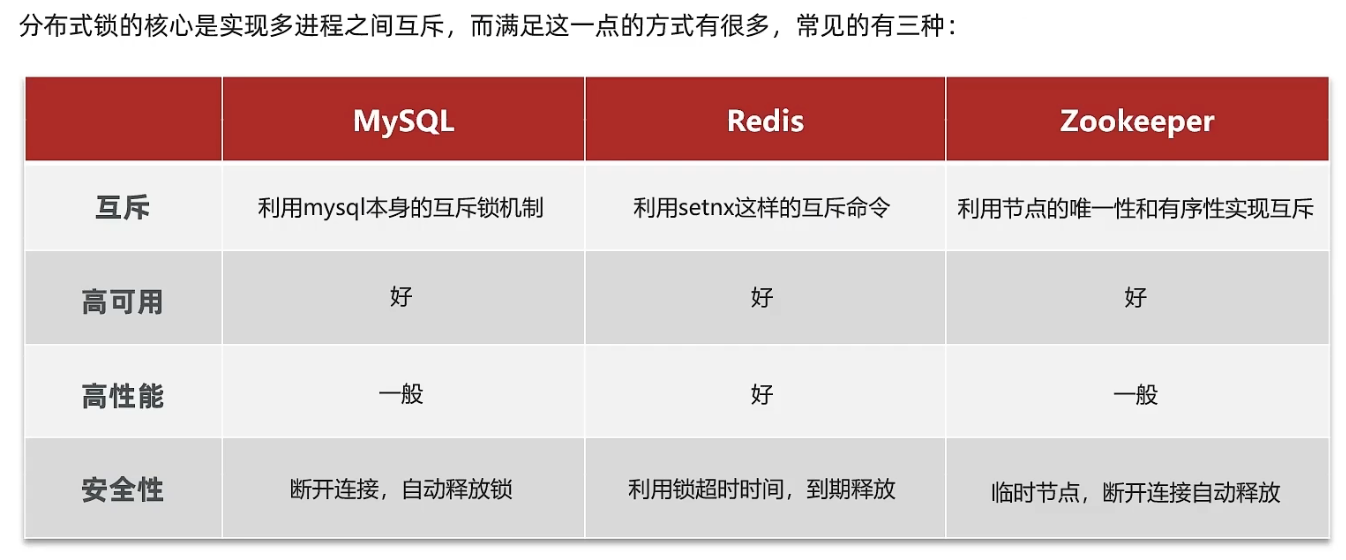
在Redis中实现分布式锁的机制很简单,可以通过Redis的SETNX命令实现。
具体实现步骤如下:
- 应用程序请求获取锁时,以锁名作为Redis的key,当前时间戳作为value,使用SETNX命令尝试设置该key的值。
- 如果SETNX命令返回1,表示获取锁成功,应用程序继续执行临界区代码;如果返回0,则表示锁已被其他应用程序获取,应用程序需要等待并重试。
- 可以设置锁的超时时间来避免锁未及时释放导致死锁,应用程序在执行完临界区代码后需使用DEL命令释放锁,或在获取锁时设置锁的超时时间(通过设置过期时间)。
- 在并发情况下,可能会出现锁已被其他应用程序释放但获取锁的应用程序仍未获取到的情况,此时需要对应用程序加入等待机制,以便在锁释放后能够立即获取锁。

以下是Java语言实现的Redis分布式锁示例代码:
1 |
|
在Java实现中,我们使用了Jedis客户端和Redis的SET命令此外,使用了Redis的eval命令以Lua脚本的方式来保证解锁的原子性。
(Redis支持通过Lua脚本进行批量操作和一些特定的业务逻辑,其原因是Lua脚本是轻量级的脚本语言,能够很好地运行于Redis内核之中,且支持强大的操作和控制。由于Lua脚本不需要经过编译而能直接执行,因此使得Redis支持实时编写和即时执行一些灵活的业务逻辑成为可能。但是需要注意的是,在Redis中使用Lua脚本时,脚本执行过程中并不是所有Redis命令都可以使用,而是有一些特殊的规则和限制。)
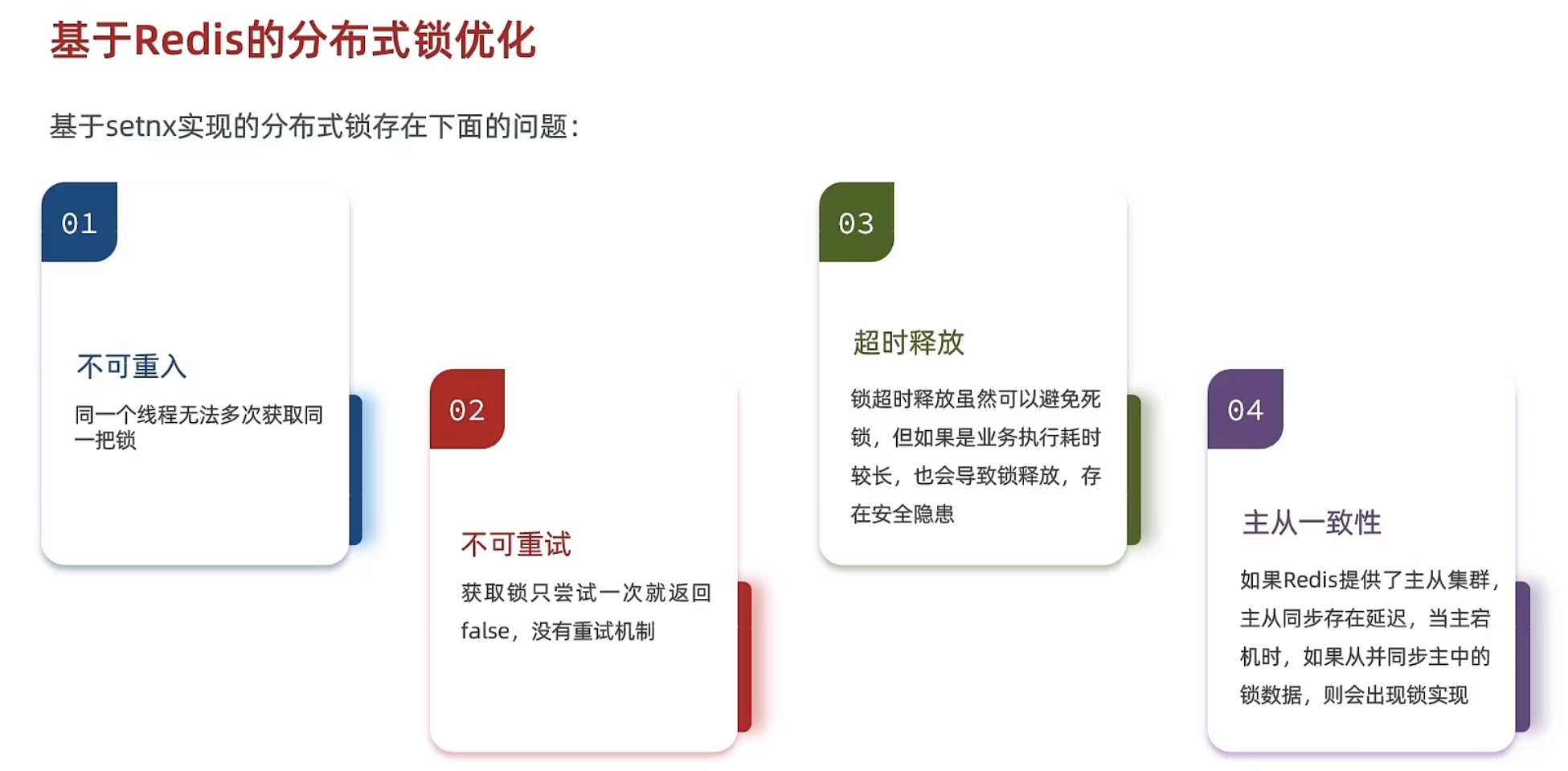
误删问题
Redis分布式锁的一个问题是误删。如果一个获得锁的客户端把自己的 key 锁数据过期时间设置太短,比如 5 秒钟,但是由于某些原因需要超过 5 秒钟才能完成任务。如果这个任务在 5 秒钟内没有完成,那么锁就会自动过期被删除。如果此时另外一个客户端获得了同一个 key 的锁,那么这个时候就存在一个危险:原本应该由第一个客户端来执行的任务可能被第二个客户端在进行。
为了避免这种情况,常见的做法是在每个客户端获取锁时为锁设置一个唯一的 标识,并在释放锁时检查 标识 是否匹配,只有匹配的 标识 才能释放锁。这样即使另外一个客户端获取了同一个 key 的锁,也不能通过释放锁的方式来误删第一个客户端的锁。同时在对锁进行续期时也需要更新 标识,避免第一个客户端的已过期的 标识 可能被第二个客户端续期。
原子性问题
Redis 中常用的分布式锁实现方式是在 Redis 中使用 setnx 命令来设置锁的 key,同时设置一个过期时间以避免锁一直存在。但是这种方式有可能存在原子性问题。
举个例子:A:假设客户端1创建了锁,但是在设置过期时间之前宕机了,那么锁的 key 就无法被删除,其他客户端会一直获取不到锁。
B:客户端1释放锁检查匹匹配之后宕机了,达到过期时间后自动删除key,客户端2又来取到了锁,结果客户端1又恢复正常了,它继续之前检查匹配之后的删除锁操作,就会删除客户端2的锁。
为了避免这种情况,可以将锁的创建和过期时间设置操作合并为一条命令(将锁的检查匹配与删除锁合并),常用的方式是使用 Redis 的 EVAL 命令,设置 Lua 脚本来保证锁操作的原子性:

1 | -- 获取 Redis 的 key,锁名称 |
(lua中数组下标从1开始)
这个脚本会首先通过 setnx 命令来尝试创建一个新锁,如果成功创建,就立即使用 expire 命令为该锁设置过期时间。如果无法创建,表示有其他客户端已经创建了锁,则直接返回 0。
这个脚本保证了创建锁和设置过期时间的原子性,避免了上述的原子性问题。同时也需要注意设置合适的过期时间,避免锁长时间存在而导致其他客户端一直获取不到锁的问题。
Redisson
前面自己实现的分布式🔒的问题:
解决方法:使用Redisson
Redisson是一个基于Redis协议的Java客户端,提供了丰富的分布式对象和服务,如分布式集合、分布式映射、分布式锁、分布式双向队列等。Redisson的目标是为Java开发者提供方便、高效、简洁的分布式解决方案,它支持Java 8和以上版本,提供了使用简单的API,可以与Redis集群和哨兵模式集成,还能够与Spring框架完美协作,为企业级应用提供高效的缓存和分布式存储支持。

redis消息队列

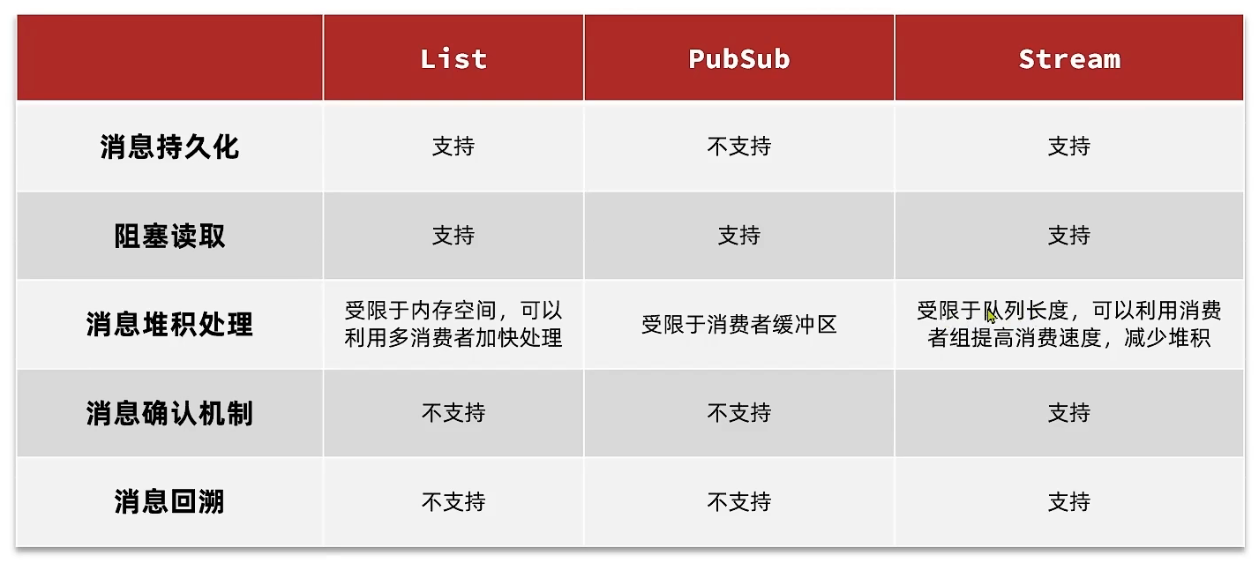
基于List
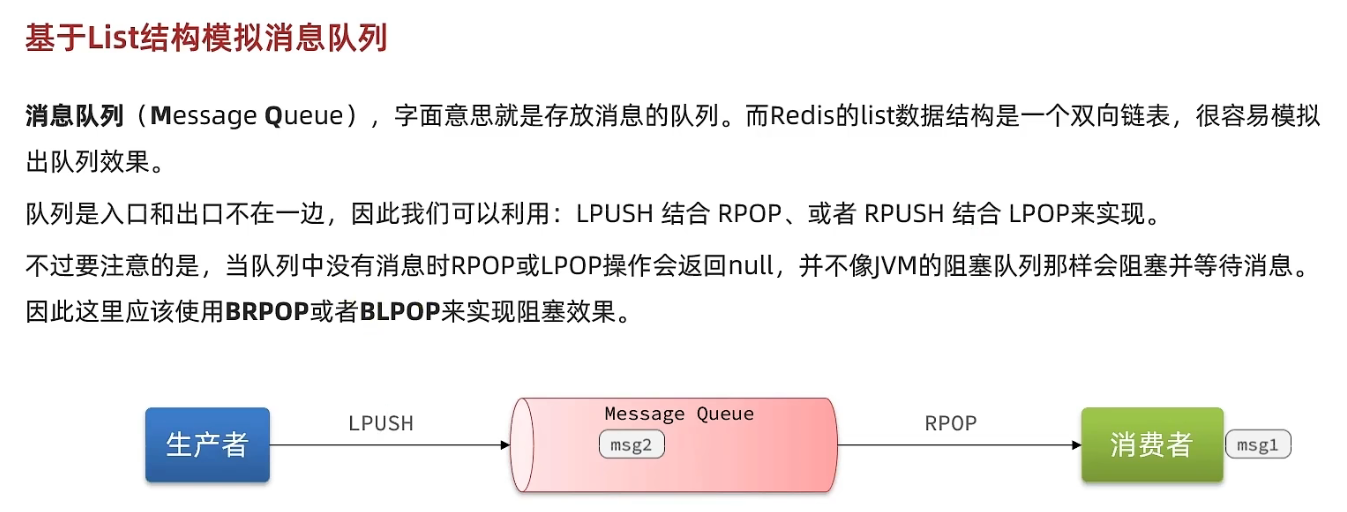

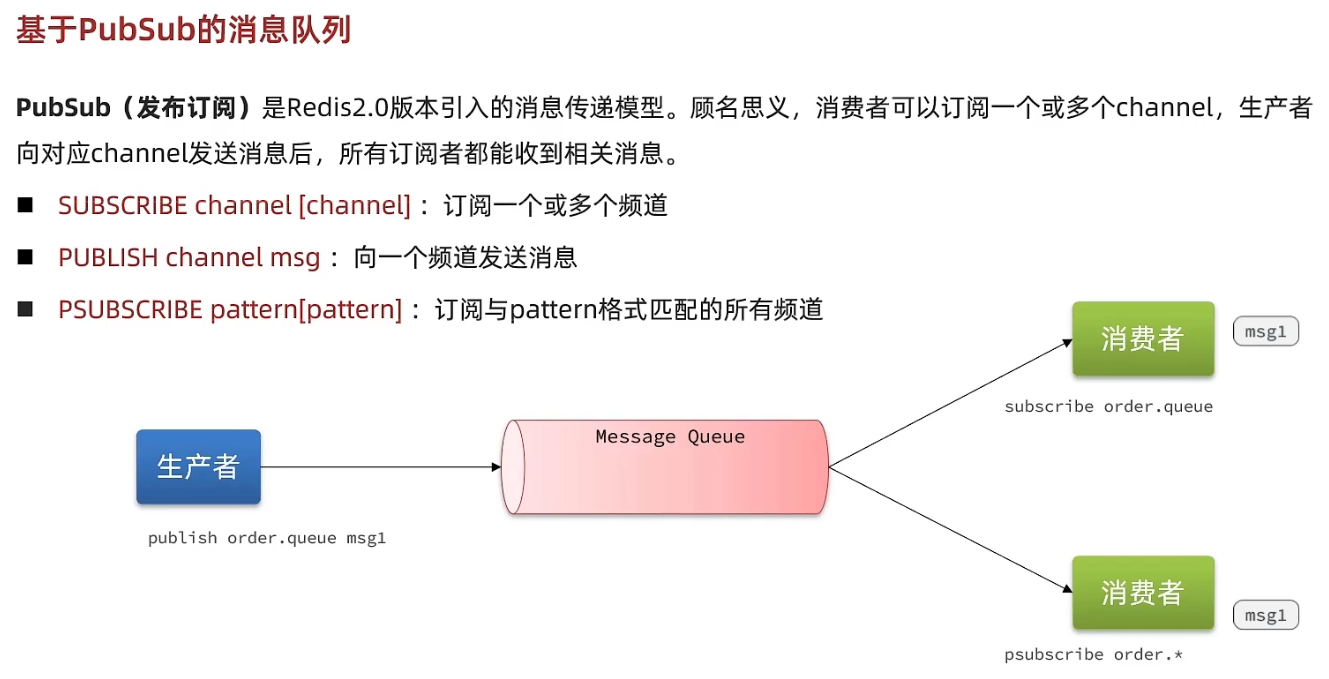
基于PubSub:

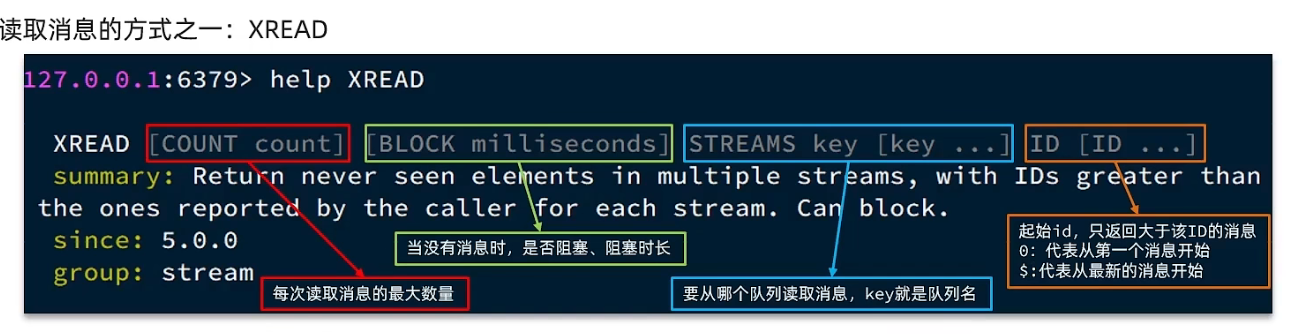
基于Stream的单消费模式

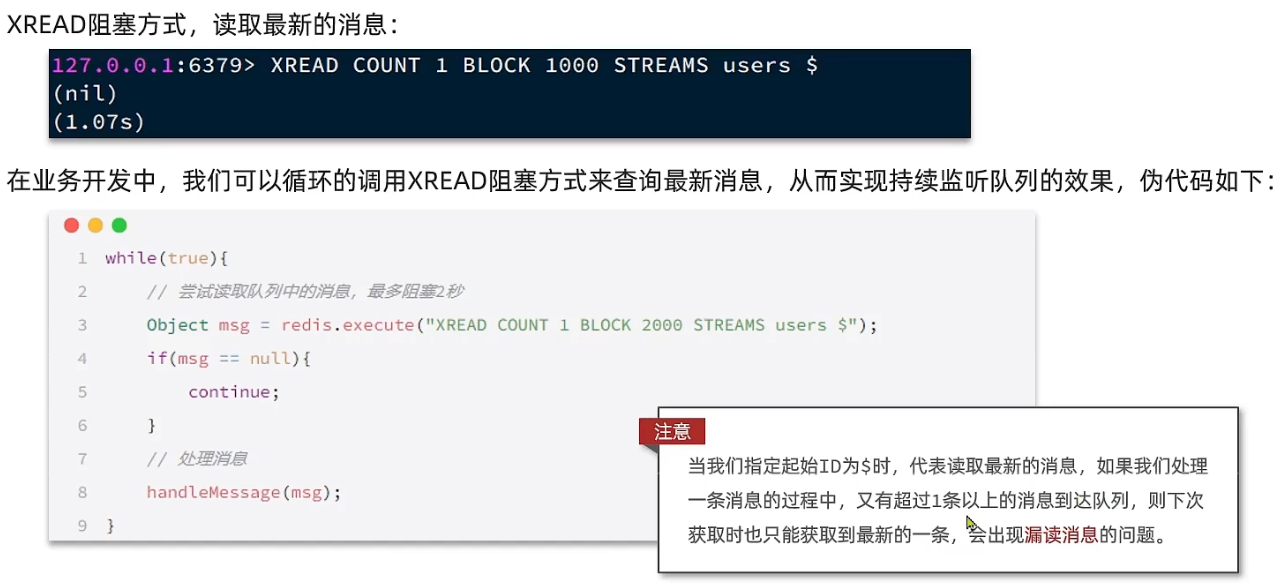

基于Stream的消费者组模式








